
P4 - Test #1
Implementing Test #1 of the Protocol
In this post, I start with the Test #1 of the Testing Protocol presented in the last post.
Student Questions
I made up a list of the following questions:

These questions are related to the following Q&A pairs in the corpus:

I wrote a loop that goes through the question list in the following way:
Construct a prompt (insert the question into a prompt template)
Identify the corpus questions that are most similar to this question
Prompt generation
The following is the prompt template for each question. most similar Q&A pairs from the corpus are attached to the end before the prompt is sent to the LLM’s API.

Most Similar Q&A Pairs
The Q&A pairs from the corpus most similar to the question to be answered is identified by using the table search utility of the vector database I am using. This is basically calculating the cosine similarity between the embedding vector of the question and the corpus question list. In lancedb, this is done as follows:
result = self.table.search(query_vector).limit(k).to_pandas()
Here, query_vector is the embedding vector of the question to be answered. The result is a pandas data frame.
If I have k=10, I get the following 10 distance values for the 10 most similar corpus questions:

I used the following to print this table:

It is not necessary to append all 10 questions (and answers) to the end of the prompt. How many should I append? There are different options:
Always the top k from the list (e.g. k=3 or k=5)
Identify the point where there is a distinct “elbow”, i.e. where the curve of the distances changes slope most sharply.
I plot the above distances below.
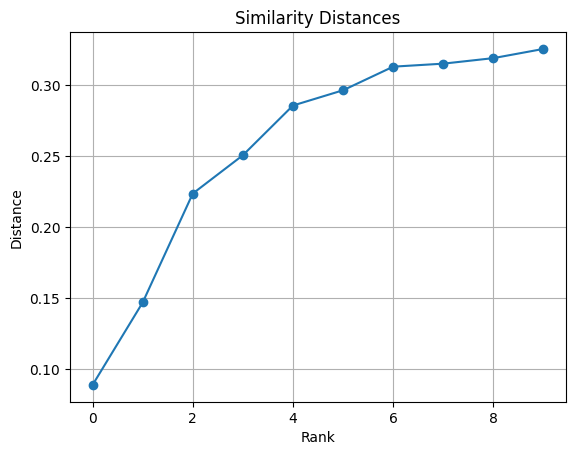
It looks like this elbow occurs between Rank=2 and Rank=3. We of course cannot manually determine the elbow for each question, there has to be an automated way. ChatGPT offered two options:
Knee detection algorithm
Fit a piecewise linear regression to detect change points
Knee Detection Algorithm

As you can see, this identified the last point. It is not very useful. ChatGPT says that this is a known weakness for automatic knee detectors:
On small datasets they tend to overfit.
If the curve flattens again at the end, it can pick the tail.
Piecewise Linear Regression

This is better. I will use k=math.ceil(Breakpoint Value), which will be 4 in this instance.
From Knowledge Base to the Prompt
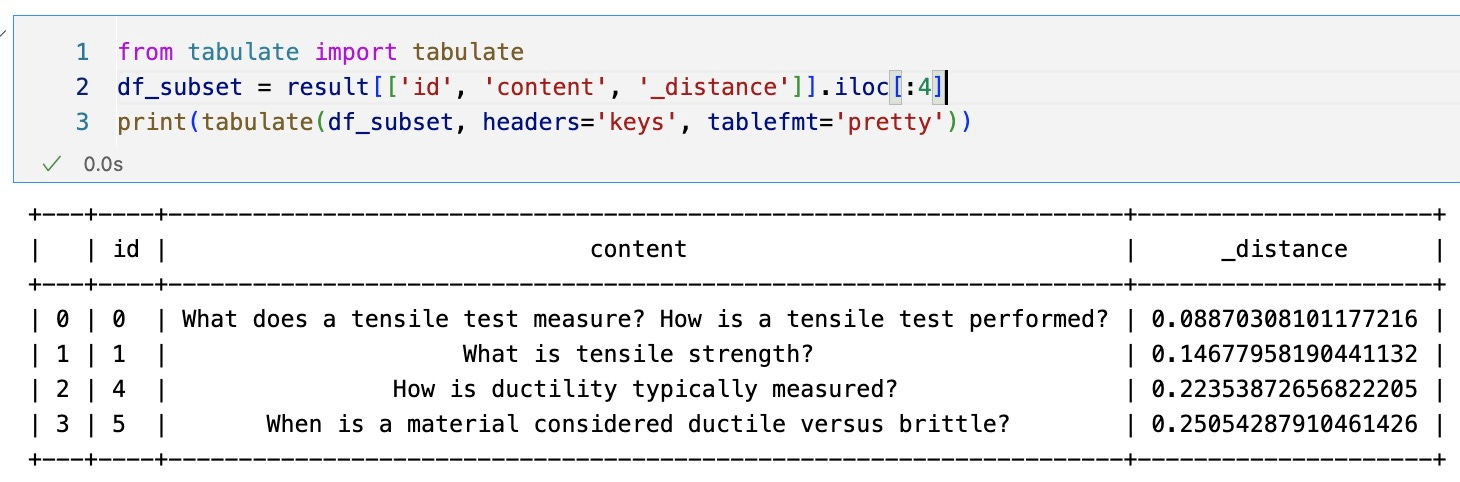
If k=4, then four questions and their answers are appened to the prompt. I tabulate the questions below for this instance (includes the code that is used to generate the table):
Results with gemini-2.0-flash
Gemini 2.0 Flash underwhelmed me. Herebelow is a summary of the Test 1 performance of this model.


Right-click and open in a new tab to make these tables readable. I will continue in the next post with another model.
gemini-2.0-flash summary
Average Mark = 2.70 out of 3; using 7610 tokens.
Paid subscribers can download the source code from github.
Extra
The following was done after this post was e-mailed to subscribers.
13 May 2025
Change the embedding model task type
Calling the embedding function, I changed the task type from “
RETRIEVAL_DOCUMENT“ to “SEMANTIC_SIMILARITY”. This corrected the wrong item pick for Question #10. Here is the new version of thhis row.

It also decided to give an answer to Question 9:

So, the average Mark is now 2.80 out of 3; using 7545 tokens.
Change the LLM
Try the model “gemini-2.5-pro-preview-05-06“. This is a newer model. Its outputs were not noticeably different although it took three times as long to get there and used up more than twice as many tokens.
So, for “gemini-2.5-pro-preview-05-06“, the average mark was again 2.80 out of 3; using 18108 tokens.
14 May 2025
The issue with Question 11
Both the previous and current Gemini LLMs failed in this question. This is the prompt sent to the API:

The question is “How many Rockwell hardness types are there?”, the best fit from the knowledge base is the Q&A Pair: “Question:What are the two main types of Rockwell hardness tests? Answer:Rockwell B (HRB), which uses a hardened steel ball as the indentor, and Rockwell C (HRC), which uses a diamond penetrator of sphero-conical shape.” Technically, the LLM is correct not answering the question because the question is on “Rockwell hardness types” and the information from the knowledge base is on “Rockwell hardness test types“. Still, a high-school student probably would be able to answer 2 based on the provided information. This is a good example showing the challenge.
Gemini App behaves the same
I asked the Gemini App using the same prompt and I got the same answer:
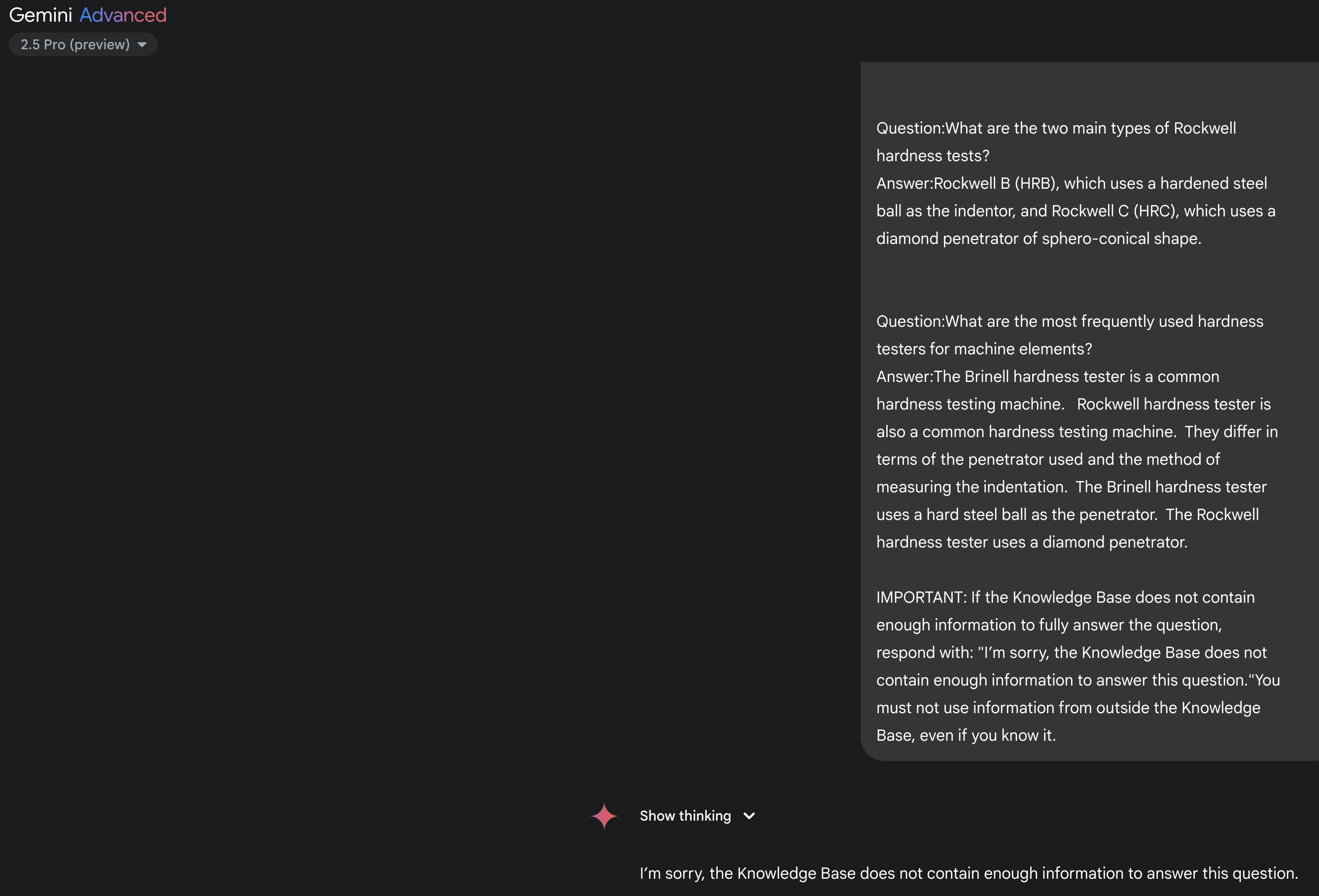
At least, it is consistent.