
LLMs are powerful tools, yet we've barely begun exploring their true potential for education. My mission in this new publication is to create practical, realistic ways for anyone—from experts to educators—to share their unique knowledge effectively using LLMs.
Note: This publication is separate from my existing Substack, "Halim’in Günlüğü—Halim's Diary." Subscribers from that list are automatically enrolled here. Feel free to unsubscribe if desired; it won’t affect your other subscriptions.
As we're increasingly realising that Artificial General Intelligence (AGI) is not imminent, we should shift our focus towards more realistic and practical applications of Large Language Models (LLMs). Large companies are already pursuing these practical pathways. My interest, however, lies with individuals like you and me—people with expertise to share, either out of passion or for monetisation.
Posting videos on YouTube is one popular method, but it's highly inefficient. YouTube neither teaches effectively nor monetises well for creators. Videos pique curiosity but communication remains one-way; viewers can't directly ask for elaboration or clarification.
I am developing a practical yet untried method to leverage LLMs for harnessing and sharing your distinct expertise. This new Substack publication will document my journey. To understand my approach, let’s briefly revisit recent developments:
When OpenAI introduced ChatGPT in December 2022, excitement and anxiety surged over how such technologies might reshape society. However, widespread disruption did not occur. The most notable impact has been in software development, largely because programming languages, APIs, and algorithms are precisely defined, leaving little room for ambiguity.
Outside coding, knowledge varies widely by context and geography. For example, mechanical engineering design in Australia adheres to specific Australian standards, distinct from those in other countries. Companies also frequently have proprietary internal standards, further complicating knowledge sharing.
Currently, two main methods attempt to address these complexities with LLMs: Retrieval Augmented Generation (RAG) and Fine-Tuning. Unfortunately, neither works satisfactorily for most practical, small-to-medium-scale applications.
RAG attempts to match user queries with relevant text passages from large knowledge bases. However, matching short queries to lengthy documents via embedding vectors often becomes inaccurate. Fine-tuning, on the other hand, requires computational resources beyond what most SMEs or educational institutions can reasonably afford.
Another significant barrier is that large AI companies focus primarily on generic, one-size-fits-all solutions. They have little incentive to tailor solutions to diverse, specific knowledge bases.
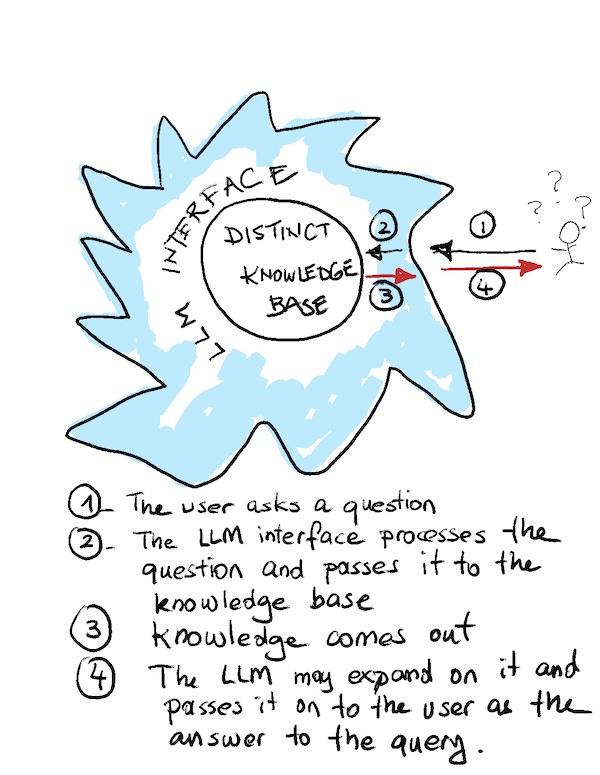
I propose a third approach. Similar to RAG, it involves structuring our knowledge base specifically for LLM interactions. We pre-format the knowledge into targeted question-answer pairs and a library of Python agents (functions) for numerical queries. The LLM then primarily serves as a natural-language communicator, bridging the user and the pre-structured knowledge.
Think of this approach through John Searle’s "Chinese Room" analogy: The LLM communicates externally with users in natural language. Internally, however, it passes user queries (converted into embedding vectors) to a handler inside the room, who identifies the best-matching pre-structured question-answer pair. The LLM then elaborates this selected response before returning it to the user.
This differs crucially from traditional RAG methods. Traditional RAG hands the entire knowledge database to the LLM, forcing it to identify relevant sections itself—often inaccurately. My approach ensures precise, relevant responses by limiting confusion and explicitly guiding the model with structured knowledge.
The primary downside, admittedly, is the initial effort required to build this carefully structured knowledge base. Large AI providers show little interest in supporting small organisations to structure their internal expertise, given their priority of scaling generic solutions.
To test and illustrate my approach, I am building an application focused on Machine Element Design for Australian mechanical engineering students. Over the next twelve months, I plan to achieve the following objectives:
Deploy the application on a commercial cloud or university server.
Populate the knowledge base with content equivalent to the MECH2100 Machine Element Design course at UQ.
Allow students to query the portal through text and receive responses in text, graphics, and numerical solutions.
Implement an assessment mode, enabling autonomous grading and feedback.
Set up practical design challenges, such as gearbox design, to test and validate the system.
Although my initial application targets Machine Design, the underlying software will remain generic, allowing easy adaptation to other specialised fields.
I firmly believe this approach isn't just another tech experiment. Over the next five years, structured LLM-powered knowledge servers could well replace platforms like YouTube, transforming how knowledge is shared globally.
I invite you to join me on this journey.