


P1 - Starting the project
Decide which tools to use; set up VS Code project folder and github repository; construct our first knowledge base; build simple a chatbot to answer queries after checking with the knowledge base
If you have not read my first post on Teaching with LLMs, do it now.
Before beginning this project, it was essential to define clear ground rules to prevent the work from devolving into ad hoc experimentation. These rules provide structure and clarity, ensuring maintainability and scalability.
Establishing Ground Rules
When we are using our python scripts as agents for the LLM, there is the danger that we can try to do too much with our python scripts.
Ground Rule 1 - Python agents strictly follow the LLM's instructions. All interactions with users are managed exclusively by the LLM. Adhering to this ensures automatic enhancement of capabilities as the LLM vendor updates their model.
Ground Rule 2 - Limit interactions with the LLM and vector databases to individual, dedicated files. I chose:
llm.pyfor all LLM interactions.vectors.pyfor embedding creation, storage, and querying the vector database.
Initially, there's no need to develop an elaborate user interface. I use a Jupyter notebook (answers.ipynb) as the entry point to process user inputs and interact with llm.py, vectors.py, and a tui.py file for user input tasks.
Ground Rule 3 - Keep it small and simple.
LLM Selection
I tried OpenAI API in February 2024. At that time, it was badly designed and unstable. I have not tried it since then. When Gemini 2.5 came out in March 2025, I tried its API through Google AI Studio and found it easy to use. Therefore, I decided to go with Gemini. As per the Ground Rule 2, all LLM stuff is in one file llm.py. Only this file needs to be changed if I decide to try another LLM in the future.
Developing a Distinct Knowledge Base
A meaningful knowledge base must contain unique or specialized information beyond general web content. My domain is machine element design, where national and corporate standards differ significantly.
Examples of potential knowledge bases include:
Real estate agent: Compiling detailed property portfolios.
Consulting firm librarian: Documenting key aspects of past projects.
Restaurant manager: Maintaining detailed menu information, including nutrition and allergens.
University Department Head: Organizing departmental offerings, graduate opportunities, and policies..
The possibilities are endless. Many of us are keepers and creators of distinct knowledge bases that are of interest to others.
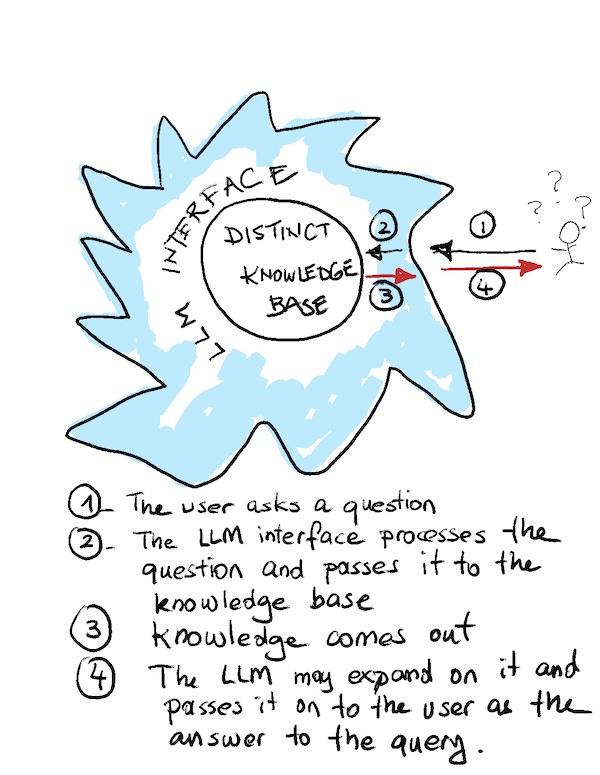
Returning to the current project, I prepared a JSON file of questions and answers that summarise what a second year mechanical engineering student needs to know in terms of engineering properties. Example Q&A pairs:
{
"Question": ["What is a tensile test?", "How is a tensile test performed?"],
"Answer": "A tensile test involves clamping a test sample of material (usually a flat or round bar) between jaws and stretching it slowly until it breaks in tension. Results are expressed in stress-strain diagrams, with stress (applied force divided by original area) on the y-axis and strain (deformed length divided by original length) on the x-axis."
}
{
"Question": ["What is creep?"],
"Answer": "Creep is the progressive elongation of materials over time when subjected to high loads continuously. It should be considered for metals operating at high temperatures (above approximately 0.3 \u00d7 melting temperature on an absolute scale)."
},
The full set of 34 questions is available on GitHub.
Duplicate questions
The JSON file allows multiple questions to map to a single answer. This flexibility ensures that semantically similar queries yield consistent responses, enhancing usability.
Creating Embeddings
The questions are converted to embedding vectors. This must be done once only and stored in a vector database. The user query is also converted to an embedding vector and is semantically matched against the question vectors. The most similar question is identified. The matching is done by your choice of the vector database library, which I will address in the next section.
I use Gemini API to generate the embeddings. GEMINI API offers four models to generate text embeddings. I have not compared them against each other and I do not know the diferences between them. At the moment, I am using gemini-embedding-exp-03-07.
Gemini API also offers four different embedding task types. These are the embedding tasks available in Gemini models:
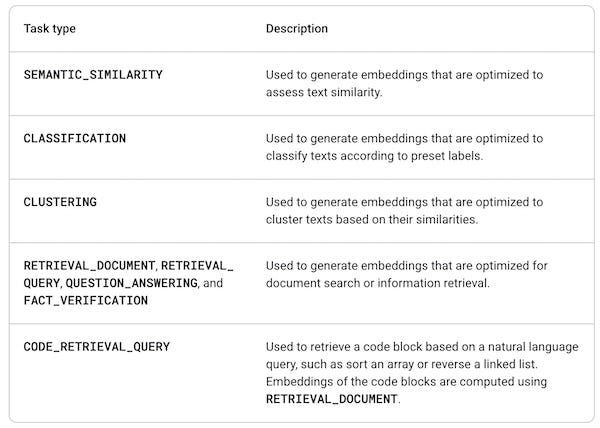
Assuming all four models have the four task types available, this means 16 embedding choices. Another choice is the size of the embedding vector. I am using 768, which was the maximum value for the first embedder I tried. I think gemini-embedding-exp-03-07 can have larger vectors but I have not tried them. One can also specify smaller embedding vectors and I will probably try smaller vectors but at this stage I do not have the time.
Selecting a Vector Database
Commonly used vector libraries include ChromaDB and Qdrant. Due to compatibility issues with Python 3.13, I opted for LanceDB, known for simplicity and ease of use. ChatGPT prepared the following table for me that compares the three vector database libraries.

Performance
Performance and Results
I implemented the described setup in Python scripts, integrating them into a Jupyter notebook for testing. Despite variations in query phrasing and even spelling errors, the system accurately retrieves relevant answers, demonstrating robustness and effectiveness.

If you click on the image and open it in your browser, you may find it easier to read the text.
A task of this nature three years ago would be difficult. Now, it feels almost a trivial achievement. I am quite happy with the result but I realise that it is only a start in my long journey.
Keep reading with a 7-day free trial
Subscribe to Teaching by using LLMs to keep reading this post and get 7 days of free access to the full post archives.