


P7 - Using ontologies
Using ontologies with an LLM
In the last post, I concluded that it was not going to be possible to use an unstructured knowledge base, such as a text file, with an LLM Tutor. We need to represent our distinct knowledge base in a structured way and somehow develop the connectivity between the knowledge base and the LLM. This is much harder than just attaching a text file with your prompt but I believe it is the only way.
Ontologies and Knowledge Graphs
Ontologies and Knowledge Graphs were introduced well before the LLMs to represent knowledge. These two concepts are very similar. In fact, a Knowledge Graph is a populated ontology. This is shown in the following figure, which ChatGPT created for me:
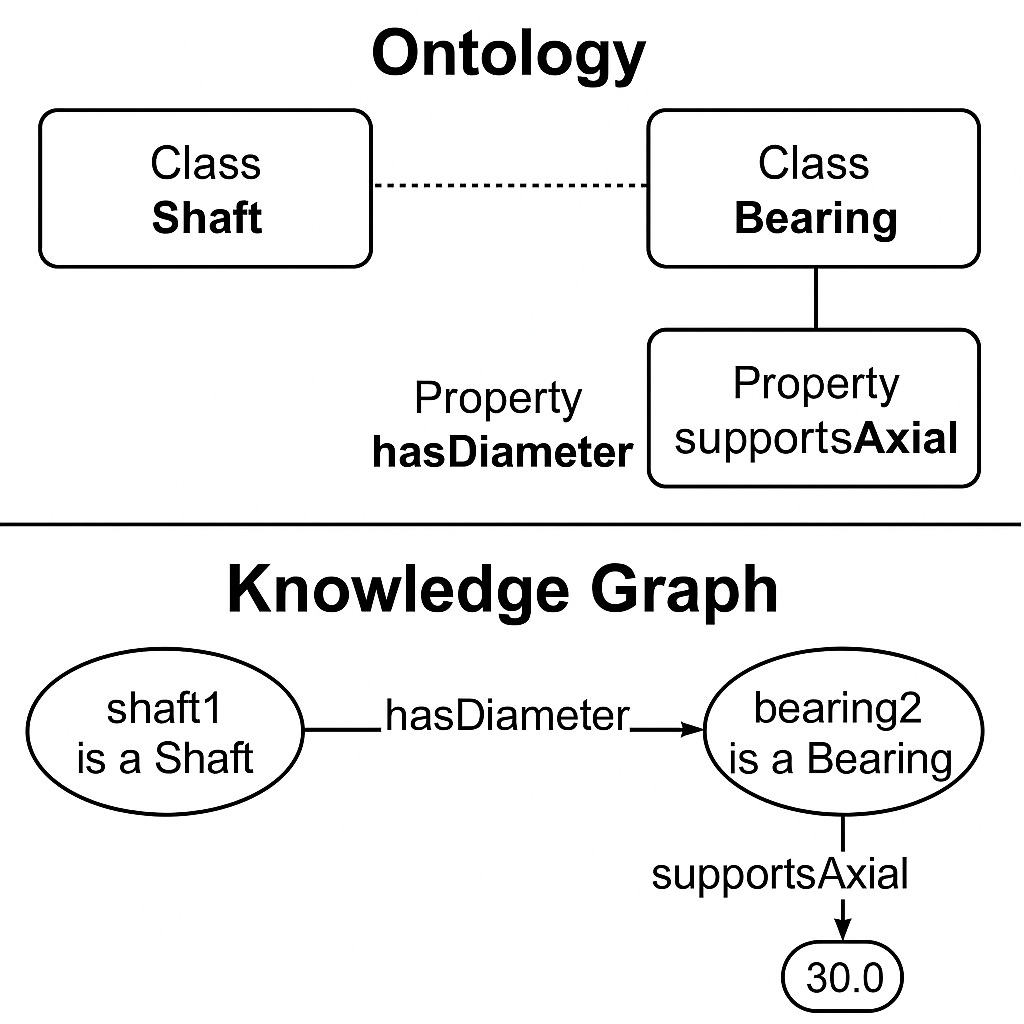
How to build an ontology?
There are dedicated software tools to construct ontologies (e.g. Protege) and knowledge graphs (e.g. Neo4j). For various reasons, I decided to construct them directly using python. I will use the library owlready2, which is installed in my venv by:
%pip install owlready2
Once the ontology is created, then one can link it to the LLM by writing special-purpose functions. The function list is given to the LLM and it picks the function that matches the user query and uses it to produce the answer.
This sounds complicated but is actually quite simple.
Ontology versus plain text
Because an ontology is structured, it will have to be better than plain text as a knowledge base. For example, we can query an ontology using SPARQL formalism. This lets us create a natural-language “front end” that turns English questions into SPARQ queries into the ontology. For example,“What are all subclasses of X?” —> SELECT ?sub WHERE { ?sub rdfs:subClassOf :X }
There are tools available althoubgh I have not tried them yet:
SPBERT: An Efficient Pre-training BERT on SPARQL Queries for Question Answering over Knowledge Graphs with an associated github repository
Proof of Concept
As a proof of concept, I created a very simple ontology. A ball bearings ontology with only two entries: NSK 6004 and SKF6203. I then interfaced it with an LLM. This is done in ontoquery.ipynb in the github repository:
The user asks this question: “"What is the maximum speed for an SKF 6203 bearing?"“
My script sends this query to the LLM and attach the ontology tools (the functions) that it can use. These functions are local python functions. In this proof of concept, I only have one function but there can be many.
The LLM identifies the function that needs to be used to answer the query and responds with the following message:
Use this function
get_bearing_property(model_number: str, property_name: str) -> str:
My script calls the function and passes on its reponse to the LLM
The LLM constructs the answer to be given to the user
My script gets this from the LLM and feeds back to the user
Details
Imports
import google.generativeai as genai
from owlready2 import *
Create Ontology
The following function creates an ontology for bearings and saves it locally as `bearings.owl`.

The function `get_ontology()` names the ontology. The argument is a unique identifier (an IRI or Internationalized Resource Identifier). The URL format is optional. A local file name is sufficient. But using a name like say http://gurgenci.org/bearings.owl ensures uniqueness. This is important if we are to share the ontology.
IMPORTANT : While a simple filename will work for a small, self-contained project, using a full IRI is the standard, professional practice.
The Tool for the LLM
To decide which function to use, Gemini performs a semantic search. The model doesn't simply look for the words from your query (e.g., "maximum speed") inside the function's name or code. It uses its Natural Language Understanding (NLU) capabilities to analyze the intent behind your query. It then looks for the function whose description (the docstring in our Python code) best matches that intent. The following is a very simple function that I use in this proof of concept demonstration:

If the LLM decides to use this tool, its reponse will have a function_call object. This is how this object looks:
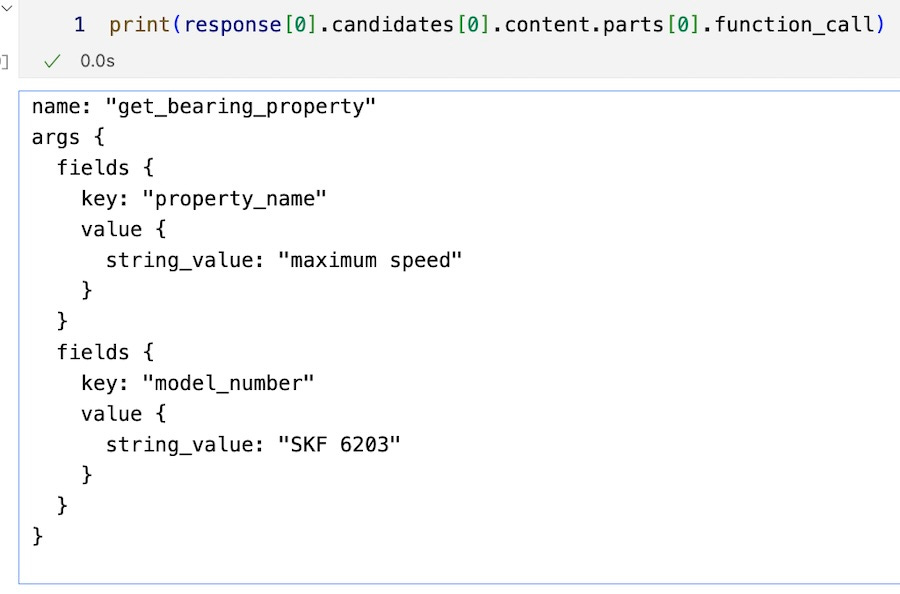
If the LLM does not select a tool, it will return a text object in its response. In this instance, the value of
response[0].candidates[0].content.parts[0].function_call
will be None.
Execution
The following is the output of this proof of concept demo:
1. User's question: What is the maximum speed for an SKF 6203 bearing?
Chat session started with model: gemini-2.5-pro-preview-05-06
2. Gemini decided to call the tool: 'get_bearing_property'
With arguments: {'property_name': 'maximum speed', 'model_number': 'SKF 6203'}
--- TOOL: Executing get_bearing_property(model_number='SKF 6203', property_name='maximum speed') ---
3. Tool execution returned: "18000"
4. Sending tool response back to Gemini to generate the final answer...
--- Final Answer ---
18000 rpm.
Reflections
Creating an ontology for an entire course is not easy but so is writing a textbook for the same contents. I think an ontology and an associated function library will be sufficient to make the LLM an expert tutor for any course.
I will now try to construct an ontology for a Machine Element Design course and will integrate it with an LLM. I will try both Gemini and OpenAI APIs.
Paid subscribers can download the source code from github.