


P6 -Test #2a - Grading T/F Questions
Starting the Test #2 protocol (from P3 - An LLM Tutor Testing Protocol - 6 May 2025)
In the last two posts (P4 and P5), I tested Gemini 2.5 and OpenAI APIs in their ability to answer student questions using the knowledge provided in a corpus, and only using that knowledge. without seeking extra information on the internet.
In this post, I start the first part of Test #2, where I ask the Gemini 2.5 the veracity of a list of statement extracted from the knowledge base provided to the LLM as a text file. The LLM is asked only to use the information provided in that text file and to answer True, False or Don’t Know on the truthfulness of each statement.
Statement List
These are the 20 statements I put together based on the corpus.
0 A tensile test measures the yield strength and the surface hardness
1 We determine the tensile strength by dividing the maximum force measured during a tensile test by the original area of the test specimen
2 The Hooke's Law defines the relation between stress and strain in the elastic region of a material
3 The Modulus of Elasticity is the maximum force measured during a tensile test divided by the original area of the test specimen
4 Ductility is the ability of a material to deform plastically before fracture
5 Brittle materials have low ductility
6 Shear yield strength is the root mean square of the tensile and the yield strength
7 The ultimate strength in shear is the ultimate tensile strength multiplied by the Poisson's ratio?
8 The Poisson's Ratio is the ratio between the ultimate tensile strength and the ultimate shear strength?
9 The shear modulus of elasticity is always smaller than Young's modulus?
10 Rockwell, Brinell and Vickers are three common hardness tests
11 There are two Rockwell tests, B and C. B is for softer materials.
12 The erosive and adhesive wear performance is the same for ductile materials?
13 Charpy and Izod tests are typically used to measure toughness.
14 Creep is defined as the percent change in the hardness of a material at elevated temperatures
15 If the carbon content in a steel is less than 3%, it is called low carbon steel
16 The purpose of annealing is the increase the modulus of elasticity?
17 The through hardness remains unchanged after annealing?
18 Martensite is a very hard and brittle phase of steel that can be formed by quenching
19 Case hardening is a process that increases the hardness of the surface of a material
Model
The LLM is gemini-2.5-pro-preview-05-06 used with the following parameter values:

Prompt
The same prompt was used for all statements. The following is the prompt sent to the LLM for Q19:
You are a university tutor assistant examining students. You ask the student True/False questions about the material included in the attached file. Consider the following question:
`Case hardening is a process that increases the hardness of the surface of a material`
Is this statement True or False based on the information in the attached file? You must answer with 'T' for True or 'F' for False. Do not use any outside knowledge or make assumptions. IMPORTANT: You must only use the information in the attached file. Do not seek external information. If the attached file does not contain enough information to answer the question, answer 'X' for Unknown. Format your answer in JSON according to the provided schema.
The JSON schema is provided
Performance
The following is the performance:
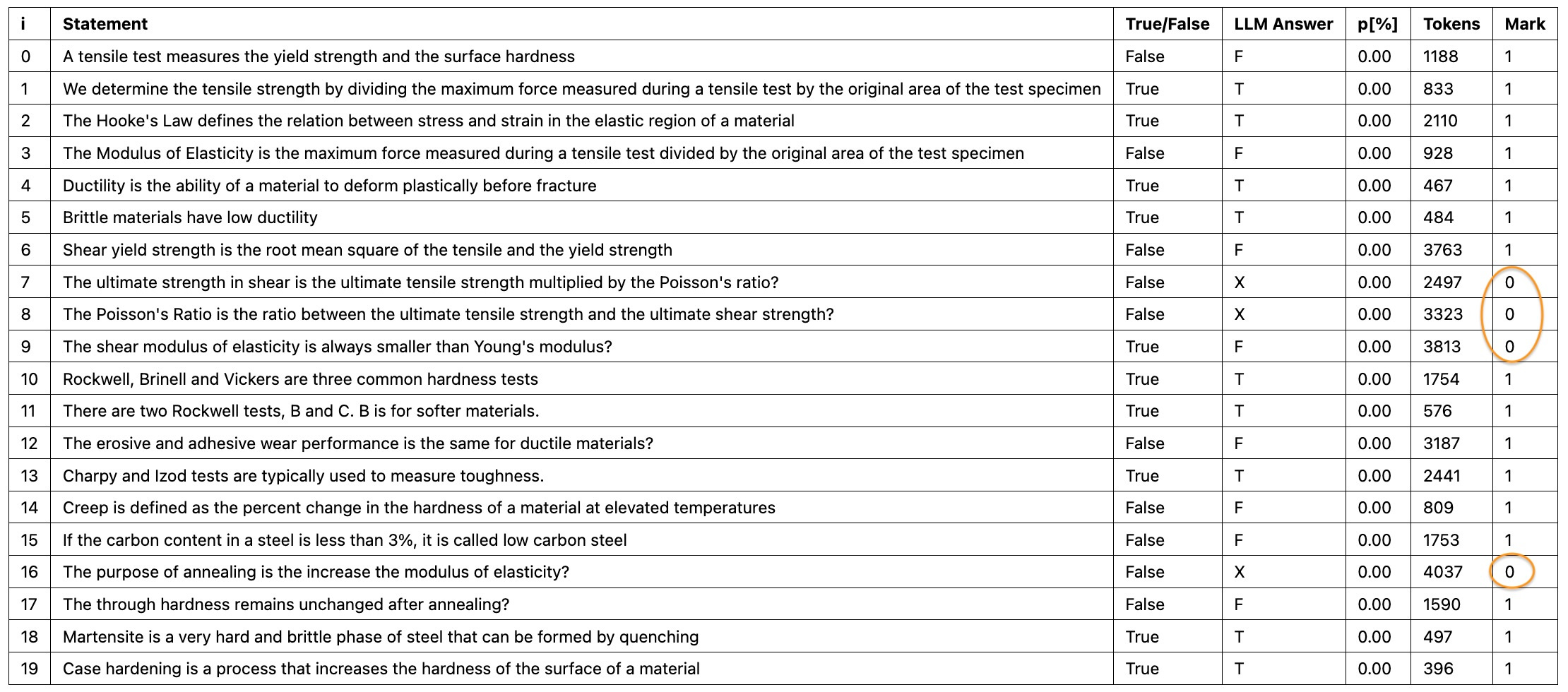
The LLM was wrong four times out of 20.
One was an error in its judgment (Q7)
In the other three, the LLM failed to arrive at a decision
The latter error usually occurred because of the output exceeded the allowed maximum number of tokens (MAX_TOKENS) and the LLM returned prematurely. Gemini chatbot suggested to specify a JSON schema instead of just telling the LLM to return “T”, “F”, or “X”. I tried that by a set_json_tfx_response_schema method to my LLM class. This instructed the LLM to answer using a JSON schema as defined below:

It is interesting that this eliminated the MAX_TOKENS errors but otherwise made the LLM more prone to end up indecisive. The following is the performance when the JSON schema is activated:
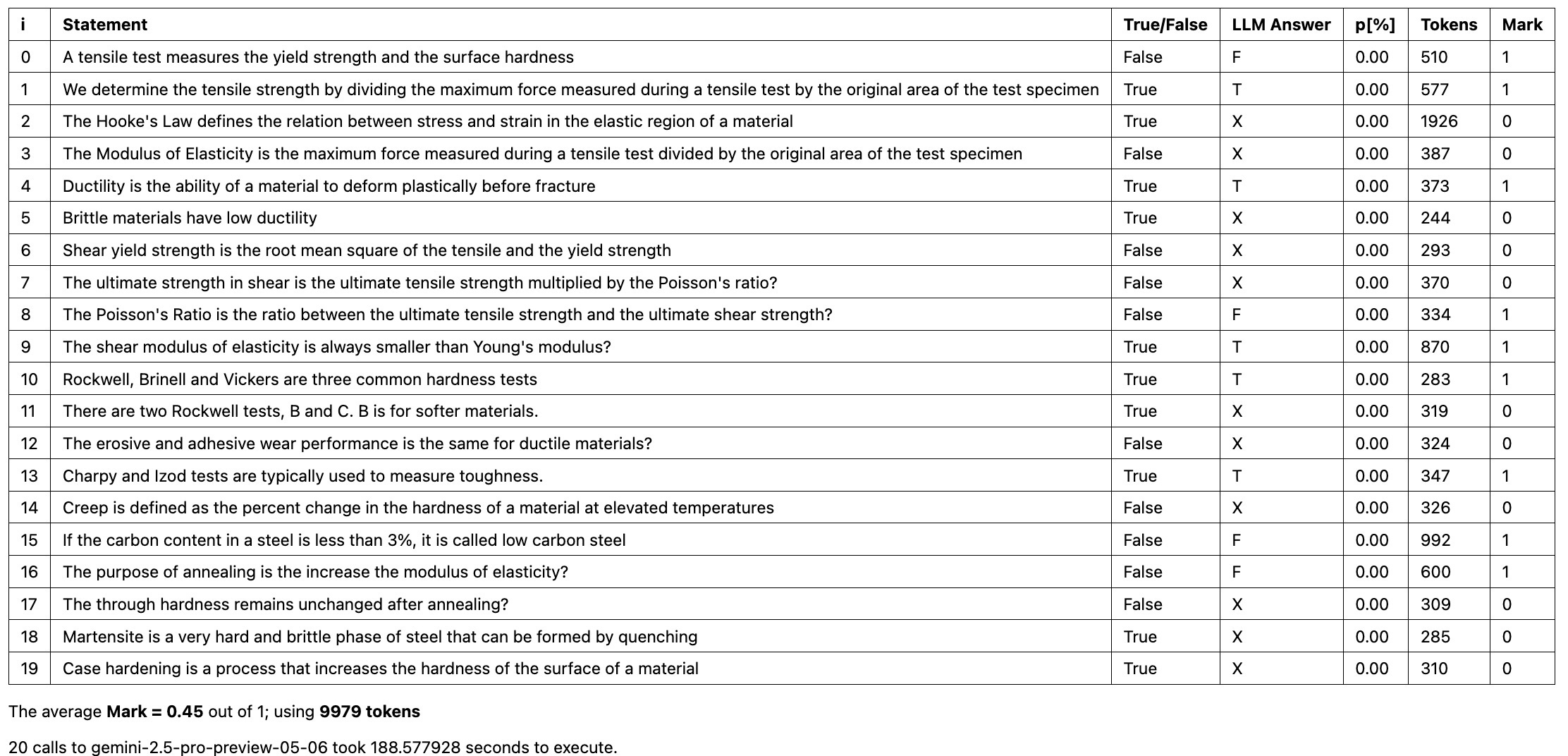
The overall performance is worse than 50%.
Two lessons from this exercise:
Large Language Models are not very good in establishing the accuracy of given statements even when they are drawn from a very small textual knowledge base, which is provided to the LLM.
The LLM performance is unpredictable because it got substantially worse when I added a JSON schema to use while responding. Everything else remained the same.
The LLM performance is unpredictable because when I rerun the same program three times in sequence, the LLM sometimes changes its opinion on some statements. This is not shown in the above images but is based on my observations.
Reflections
I am now convinced that it is not going to be possible to use an unstructured knowledge base, such as a text file, with an LLM Tutor. I had suspected this, based on my understanding of the way LLMs work, e.g. read my March 2023 blog post. But it is good to get it confirmed by one’s own work.
What does this mean? This means that we need to represent our distinct knowledge base in a structured way and somehow develop the connectivity between the knowledge base and the LLM. This is much harder than just attaching a text file with your prompt. I stop execution of my Test protocols now. The tests were designed to test the ability of an LLM to work with a text-based knowledge base. We now know that the LLMs will not be able to use a text-based knowledge base. So there is no utility in continuing with the rest of the protocol.
Paid subscribers can download the source code from github.