


P5 - Continue with Test #1
Implementing Test #1 of the Protocol using OpenAI and more
The last post used Gemini to do Test #1 of the Testing Protocol.
This post will continue to Test #1:
repeat the same but will use OpenAI.
upload the corpus as a file before the chat starts and ask the LLM to answer using the information in that file.
OpenAI Performance
LLM Name:
gpt-3.5-turboEmbedding model:
gemini-embedding-exp-03-07
The structure of OpenAI API calls is slightly different but I hide that difference in the LLMOpenAI class that is included in call_openai.py. The jupyter notebook t1.ipynb is almost exactly the same as in the previous post but it calls call_openai.py rather than call_gemini.py.
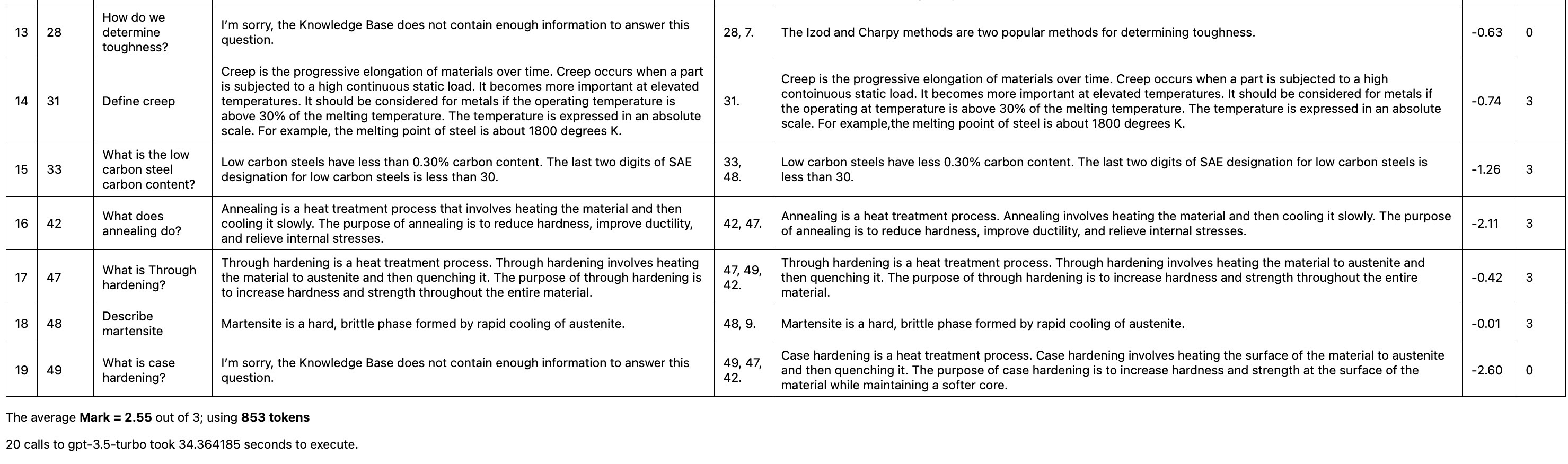
The performance of the openAI model gpt-3.5-turbo is worse than gemini-2.5-pro-preview-05-06. Here are the results:

Back to Gemini
Send Entire Corpus to LLM as the Context
Above and in the last post, I identified k questions from the corpus that are closest to the “user query”1 .
Now I will try using the entire corpus text as the context.
We do not need to resend the entire corpus with each query. Gemini allows us to upload the text file once and refer to it during the queries.
The uploaded file is not associated with any LLM. It is just put on the shelf. To use it with a particular LLM, you need to assign it to that LLM. I do it like this:

The New Prompt
The prompt also needs to be changed of course.

The results were excellent. The LLM (gemini-2.5-pro-preview-05-06) answered all questions accurately:

To get this performance, I had to present the corpus as continuous text format. I did this by only including the answers.
Thge Question and Answer was format did not work as well. I think it was confusing the LLM.
This may have been the issue in Test1a. So I try it again but this time send only the answer text for the closest k corpus entries.
Try Test1a again
So I did the Test1a again but the performance was even worse than the first one:
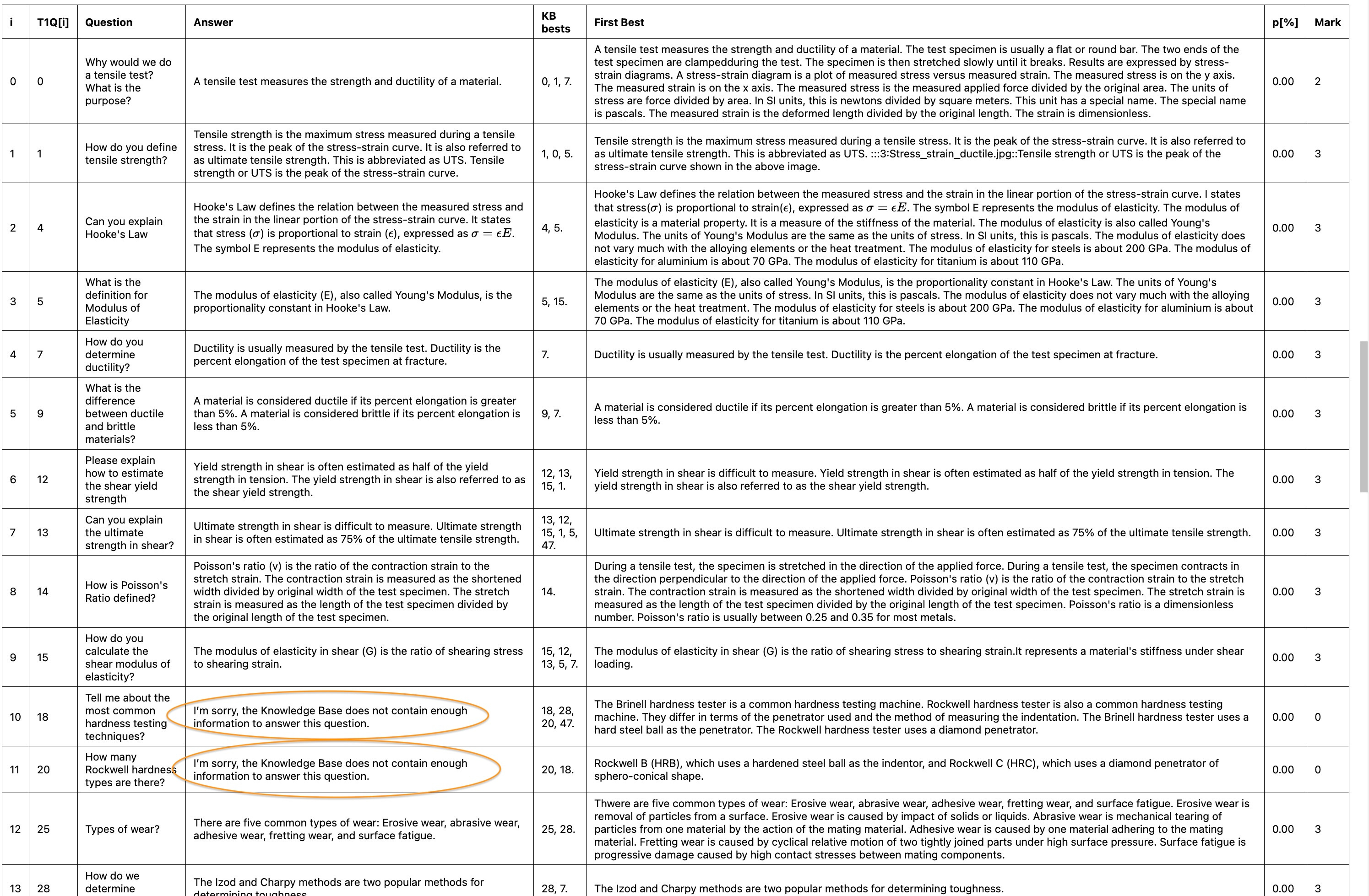
This time there are TWO unanswered questions. The first time, there was only one, in spite of the LLM being less competent then (gemini-2.0-flash then and gemini-2.5-pro-preview-05-06 now).
Reflections
This is the end of Test #1. The results are encouraging.
I found it interesting that the entire corpus text worked better than finding the best fits and using only them as the context. I would not have guessed this result.
Hallucinations are Real
This story below shows why I am going into all this trouble to restrain the LLM into only my distinct knowledge base.
Ted Gioia in his Substack post refersto the “Summer Reading List for 2025” published in the Chicago Sun-Times. This is a US newspaper with an average print circulation of 60,000. The reading list they published gave glowing reviews to books that don’t exist. Obviously, someone asked an LLM to prepare a “Summer Reading List” and neglected to check the list against hallucinations.
Paid subscribers can download the source code from github.
The T1ASK list in t1.ipynb are the user queries and each is modelled after a question in the corpus, T1Q says which one.